I’ve been working on multiple projects over the past couple years and most of them need to consume images of some flavor across multiple data centers (we have 10 in our metro with multiple network spaces). One team was managing vCenter templates (in case automation platform failed or a custom deployment needed) while an automation team was doing OS ISO builds for every VM. The time to deliver and support these options were not scaling to our needs.
To simplify this and add new features (such as security scanning of images before being deployed), a few of us decided to revamp this process. We wanted to use a couple newer tools along with established tools already in place by our development teams.
While working on the project it was easy to find blog posts on small parts of each step (referenced within the series so I won’t recreate them) but there wasn’t any posts putting it all together. I hope this series paints that picture for others that are looking to do the same thing.
This series of posts covers the overall process, some particular challenges we overcame along the way, and specifics on my contributions to the project. It will take multiple posts to get through it all so hang on for the ride.
Let’s get started by painting the overall picture. We can’t architect a solution without requirements and goals
Image Pipeline Goals and Requirements:
- Fully automated OS Build Process
- Images must be distributed the same day they are built
- Build process code changes must go through review process before going into production
- Fully automated distribution of images to all data centers
- OS Deployment process uses new OS images instead of ISO build process
The next thing we must review is our environment. Again, we have multiple data centers within multiple sites and even some network boundaries within some of these data centers (Corporate, PCI, Production, etc.)
Environment:
- Roughly 40 vCenter Servers globally running various vCenter 6.5 and 6.7 versions
- Over 13,000 hosts ranging from ESXi 5.5 through 6.7
- JFrog Artifactory already implemented with multiple replication targets globally
- Jenkins/Spinnaker/GitHub already running
- vSphere related scripting hosts already running for environment data collection/reporting
High-level Architecture:
To get started we needed a place to build images. Eventually there will be many builds running at the same time (OS versions, Solution software layering, etc.) and we wanted them to complete as soon as possible. This led us to using a dedicated cluster so we could grantee resources.
Within each vCenter there is a “Template” host were VM Templates and ISO files are stored to complete previous VM build processes. To make managing these items easier (both in the past and with the new process), we have a single LUN shared to all template hosts within a single site or network boundary. I’ll go into more detail on this setup in Part 1 of this series.
We will utilize existing Artifactory instances to replicate items across network boundaries. Then we will utilize existing scripting servers to run an automated process that pulls images from Artifactory and delivers them to Content Libraries (more details on this below). It is already being used for container and core software replication so firewalls were already open to those network spaces.
The following shows the data path (both vCenter 6.5 and 6.7) and the tools our process utilizes. The right side is repeated for each site and/or network space.
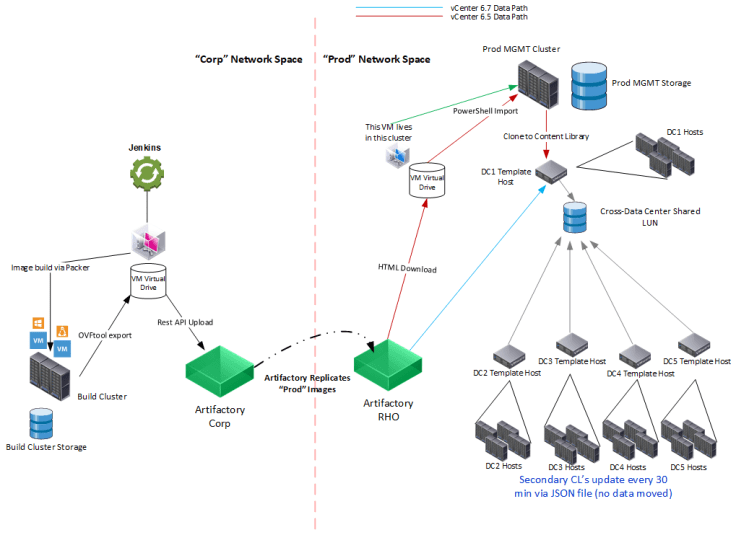
Some of the layout above may seem off. We either have environmental or technical reasons for them that will become more evident in subsequent posts.
Tools:
After some planning sessions we decided to utilize the following tools to meet our requirements.
- Code will be stored within internal GitHub server and auto-updated downstream when approved merges happen.
- Jenkins/Spinnaker is leveraged to orchestrate multiple automation components within OS Build process and moving images to Artifactory.
- Packer will be used to create OS images along with scripts to customize them, as needed.
- Existing artifact distribution tool (Artifactory from JFrog) replicates to different network spaces.
- Existing environment data collection “scripting” servers will be used to automate moving images stored within Artifactory to ONE Content Library within each network boundary.
- vSphere Content Libraries will replicate images between Content Libraries within a single network boundary
- Current VM delivery automation tool will be used to deploy VMs from Content Library images instead of full builds. Deployment code will be updated.
Now that the foundation is set, I’ve broken it down into the following sub posts:
- Large Scale Image Pipeline – Part 1 – Content Library Setup
- Large Scale Image Pipeline – Part 2 – Image Build Process
- Large Scale Image Pipeline – Part 3 – Query Artifactory via PowerShell
- Large Scale Image Pipeline – Part 4 – Importing OVA’s to vCenter 6.5 Content Libraries
- Large Scale Image Pipeline – Part 5 – Importing OVA’s to vCenter 5.7 Content Libraries

Leave a comment